RでANCOVAをしよう!! (1)

- アウトライン
-
- 作成日: 2026/2/7
- 更新日: –
はじめに
ヒト臨床試験 (ヒト試験) の統計解析では、血液・尿などの臨床検査値を「介入前後でどれだけ変わったか」で評価したくなる場面が多くあります。実際、ベースライン (0週) と最終評価 (n週) が揃っていれば、まずは変化量 (post − pre) を作り、t検定などで群間比較する、という運用は直感的で分かりやすい方法です。
一方で、変化量には見落とされやすい落とし穴があります。ベースラインが大きい人ほど変化もしやすい (あるいはしにくい) といった性質があると、観察された群差が「介入効果」なのか「もともとのベースラインの違い」なのかが混ざってしまい、比較可能性が揺らぎます。とくに機能性表示食品の実務では、群間差がないのに、前後差の差だけで「有意」として取り扱うという解釈が問題視された経緯もあり、統計解析担当者としては「説明責任を果たせる群間比較」を、再現性のある形で実装できることが重要になります。
そこで本稿では、ベースラインの影響を統計モデルで調整し、介入効果を公平に評価する代表的手法である ANCOVA(共分散分析) を取り上げます。さらに、解析の現場で役立つように、CDISC標準(ADaM/BDS)の形式で整備された臨床検査データ (tidyCDISC::adlbc) を例に、Rで「項目×時点×指標 (AVAL/CHG)」を自動で回せる実務スクリプトとしてまとめます。
変化量を使ってよい条件と、使うならどう調整して説明するかを、理屈と実装の両方から押さえることが本稿の目的です。
変化量を群間比較できるか?
2.1 変化量の群間比較に関する議論
変化量の群間比較に関する議論は、2019年2月25日のASCON科学者委員会からの変化量の群間比較に関する疑義よりはじまりました。
| 0週 | n週 | 変化量 | |
|---|---|---|---|
| プラセボ群 | P0 | Pn | P0とPnの差 (A) |
| 試験群 | T0 | Tn | T0とTnの差 (B) |
| 群間比較 | P0とT0の差 | PnとTnの差 | AとBの差 |
機能性表示食品の効果判定に関する新たな項目の設定についてより引用、改変
PnとTnの差 (群間差) がないにもかかわらず、参考値AとBの差 (前後差の差) があることをもって「群間差あり」とする届出がありました。この論文を届出資料として認めることについては疑義があり、消費者庁の見解を求めることとしました。
そして、2020年6月11日にASCON科学者委員会よりICH-E9「臨床試験のための統計的原則」に基づくことで、変化量の群間比較における有意差をもって有効性を謳うことを認めることとなりました。
| ■ASCON科学者委員会機能性表示食品の評価判定基準 (2020年6月改定・8/1 微修正), 5. |
|---|
| 「機能性表示食品に対する等関係法令基づく事後的規制 (事後チェック) の透明性」 (2) イに基づき、「主要アウトカム評価項目における介入群と対照群の群間比較で統計的な有意差 (有意水準5%) が認められていない場合」は根拠論文として認めない。なお群間比較を行う際、臨床試験の測定値をそのまま使用せず、試験前後の変化量などに変換した値を使用する場合には、平成10年11月30日付厚生省医薬安全局審査管理課長通知・医薬審 第 1047号『「臨床試験のための統計的原則」について』「Ⅴ. 5.4 データ変換」に基づき、 その理論的根拠が明確に説明されている場合のみ根拠論文として認める。 |
ASCON科学者委員会機能性表示食品の評価判定基準 (2020年6月改定・8/1 微修正) より引用
2.2 ICH-E9「臨床試験のための統計的原則」とは?
ICHガイドラインの有効性 (Efficacy) 分野に位置づけられる ICH-E9 について説明します。ICH-E9の正式名称は「Statistical Principles for Clinical Trials (臨床試験のための統計的原則)」です。
- ICH 医薬品規制調和国際会議
ICHとは、医薬品の承認に必要な品質・安全性・有効性の評価基準を国際的に統一することを目的に作られた国際的な枠組。
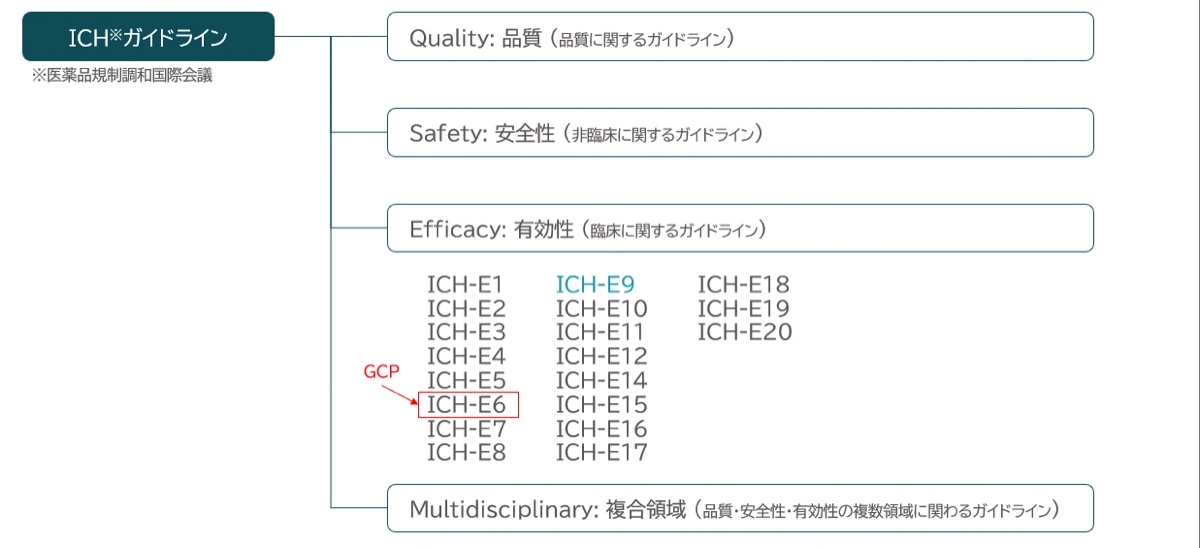
ICHガイドラインは、品質、安全性、有効性、複合領域に分類されています。
上記の図に示されているとおり、ICH-E6 (GCP) が臨床試験の実施や体制を定めているのに対し、ICH-E9は統計解析と結果解釈の原則を定めた文書です。
2.3 「臨床試験のための統計的原則」の目的
ヒト臨床試験 (ヒト試験) において、対象者全体の集団 (母集団) から試験参加者 (標本集団) を抽出し、介入を行い、データを収集して得た介入効果の推定値は以下のように構成されています。
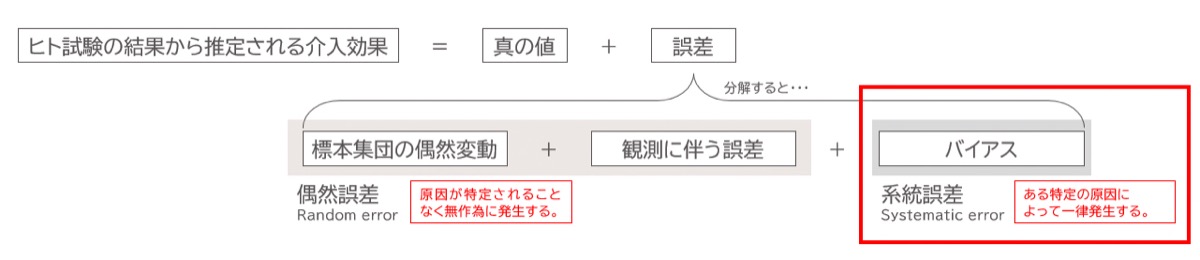
試験結果から得られる介入効果の推定値は、「真の効果」+「誤差」で構成されます。
このうち、「誤差」はさらに以下の2つに分けられます。
-
- 偶然誤差 (ランダムエラー)
- 標本集団の偶然変動 (標本集団を抽出したことによるばらつき)や、観測に伴う誤差 (測定に伴う不確実性) によって生じます。原因を特定できず、無作為に発生するのが特徴です。サンプルサイズを増やしたり、測定精度を高めたりすることで小さくできます。
-
- 系統誤差 (バイアス)
- 特定の原因によって一方向に生じる誤差で、無作為ではありません。例えば、被験者選択、測定方法、解析手法、結果の解釈などに由来します。サンプルサイズを増やしても基本的には解消されません。
ICH-E9では、このバイアスを最小化し、推定の精度を最大化することを統計的原則の重要な目的としています。そのため、試験の計画・実施・解析・解釈の各段階で、どのようなバイアスが入り得るかを事前に想定し、可能な限り排除・制御することが求められます。
| ■ICH-E9 臨床試験のための統計的原則 (平成10年11月30日付医薬審第1047号),I. はじめに, 1.2 適用範囲と方向性 |
|---|
| (省略)・・・ 本ガイドラインに述べられている原則の多くは、偏りを最小にし、精度を最大にすることを目的としている。本ガイドラインでは、「偏り (バイアス)」という用語を、「臨床試験の計画、実施、解析及び結果の解釈と関連した因子の影響により、試験治療の効果の推定値と真の値に系統的な差が生じること」という意味で用いる。偏りを低く抑えるためには、偏りの潜在的な原因を可能な限り明らかにすることが重要である。偏りの存在により、臨床試験から妥当性のある結論を導くことが困難になるおそれがある。・・・(以下、省略) |
ICH-E9 臨床試験のための統計的原則 (平成10年11月30日付医薬審第1047号) より引用
2.4 変化量をエンドポイントとして採用する条件
上述の通り、臨床試験のための統計的原則は、医薬品開発、いわゆる治験において「バイアスを最小にして精度を最大にすること」を目的とした統計解析に関連するガイドラインです。
ASCON科学者委員会は、このガイドラインの「5.4 データ変換」を参照することを推奨しています。全文を以下に示しましたが、これらを要約すると
- 「変数の変換は、計画時に決定する。」
- 「プロトコルまたは解析計画書に記載する。」
- 「変数として、臨床的な解釈ができる。」
- 「統計学的に問題がない。」
の4つの条件を満たすことで変化量をエンドポイントに採用できることがわかります。
| ■ICH-E9 臨床試験のための統計的原則 (平成10年11月30日付医薬審第1047号),Ⅴ. データ解析上で考慮すべきこと, 5.4 データ変換 |
|---|
| 重要な変数を変換するために必要な判断は解析の前に行い、先行する臨床試験での類似データに基づいて治験実施計画立案時に行うのが最善である。変換 (例えば、平方根、対数) を行うことは、主要変数については特に治験実施計画書に明記すべきであり、その理論的根拠を述べるべきである。統計手法の前提を満たすことを保証するための変換の一般的な原則は、標準的な教科書に書かれている。また、特定の変数についての変換の慣例的方法は、多くの臨床領域別に開発されてきている。変数を変換するかどうか、変換するのであればどのように変換するかという判断は、臨床的な解釈を容易にする尺度を選択するという観点も含めて行われるべきである。同様な配慮は、基準となる時点での値からの変化、基準となる時点での値からの変化割合、繰り返し測定の「曲線下面積」、又は二つの異なる変数の比、といった新たな変数の導出の際にも行うべきである。新たな変数の臨床的解釈は注意深く検討されるべきであり、その正当性も治験実施計画書に述べるべきである。密接に関連した話題が2.2.2節に述べられている。 |
ICH-E9 臨床試験のための統計的原則 (平成10年11月30日付医薬審第1047号) より引用
2.5 変化量が孕む統計学的諸問題
変化量をエンドポイントに採用するための4つの条件のうち
4.「統計学的に問題がない。」
について解説します。
変化量は介入後の測定値から介入前の測定値を減算した値で、変化率は変化量を介入前の測定値で除した値です。このように、変化量はもともと2つの測定値 (2標本) があったものを1つの値 (1標本) に要約しており、「本当に比較してよいのか」、「要約によって意味が歪んでいないか」を考えずになんとなく計算している方も多いかと思います。
【変化量が問題になるケース】
|
介入前 |
介入後 |
変化量 |
変化率 |
|---|---|---|---|
| 10 | 1 | -9 | -90% |
| 100 | 91 | -9 | -9% |
上記の例では、
10 → 1 (変化量 −9)
100 → 91 (変化量 −9)
と、変化量は同じ−9ですが、
- 前値が小さい10 → 1は大きな低下
- 前値が大きい100 → 91は小さな低下
と、臨床的な意味は異なります。
このように、介入前の値が大きいほど変化しやすい特性を持つデータでは、変化量は前値の影響を強く受けてしまい、比較可能とは言えません。変化量が意味を持つのは、介入前の値に左右されず、変化の大きさそのものが一定の意味をもつ場合、前値が変化量に影響しない (間隔尺度的な変化) 場合のみです。
イメージがわきにくいと思いますので、図で解説していきます。
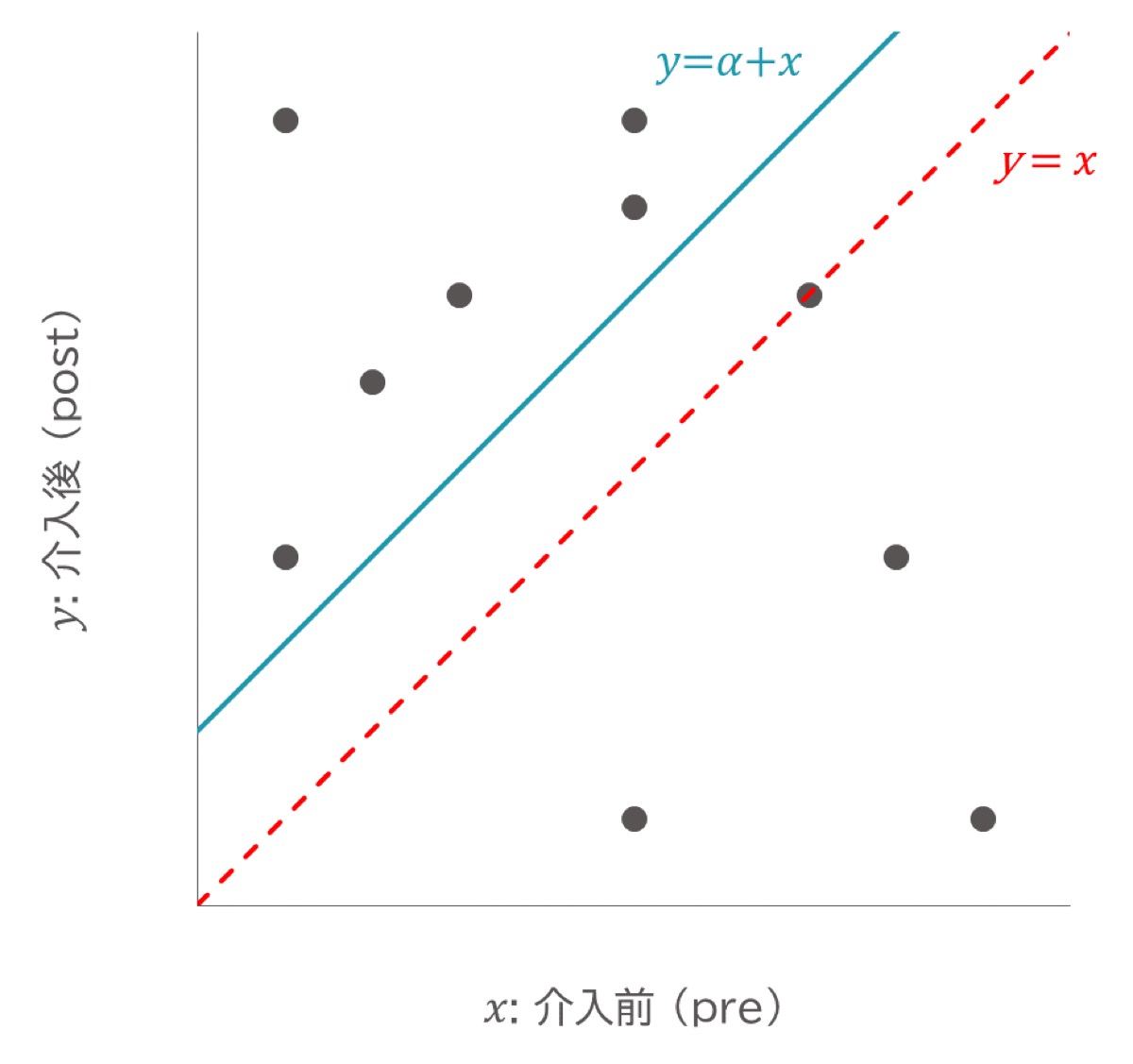
介入前 (pre) を𝑥、介入後 (post) を𝑦とした場合、以下の回帰直線で示すことができます。
変化量d は、𝑦−𝑥であることから以下の式で示されます。
変化量𝑑 は、 上式より𝑥 (介入前の測定値) の影響をうけていることがわかります。
しかし、𝛽≒1のときは介入前の測定値の影響をうけません。
「\(\text{y=α+x}\)」が成り立つときに変化量をエンドポイントとして採用することができます。
以上より、変化量は「𝑦=𝛼+𝑥」が成り立つとき、変化率は「𝑦=𝛽𝑥」が成り立つときにエンドポイントとして採用することができることがわかりました。
しかし、このような条件が厳密に成り立つ状況は、ヒト臨床試験においてはほとんどありません。
そのため、変化量に対する t 検定などの群間比較は、比較可能性に疑義が生じやすい状況にあるといえます。
一方で、変化量そのものを報告することに意味がある変数も存在します。この問題は、介入前の測定値を解析時に調整することで対応可能です。
| ■Guideline on adjustment for baseline covariates in clinical trials,5. Criteria for including OR excluding a covariate in the primary analysis, 5.6. ‘Change from baseline’ analyses |
|---|
| When the primary analysis is based on a continuous outcome there is commonly the choice of whether to use the raw outcome variable or the change from baseline as the primary endpoint. Whichever of these endpoints is chosen, the baseline value should be included as a covariate in the primary analysis. The use of change from baseline with adjustment for baseline is generally more precise than change of baseline without adjustment. Note that when the baseline is included as a covariate in a standard linear model, the estimated treatment effects are identical for both ‘change from baseline’ (on an additive scale) and the ‘raw outcome’ analysis. Consequently if the appropriate adjustment is done, then the choice of endpoint becomes solely an issue of interpretability. |
Guideline on adjustment for baseline covariates in clinical trialsより引用
欧州医薬品庁 (EMA) からは、臨床試験におけるベースライン調整に関するガイドラインが公表されており、変化量を群間比較する際には、ベースラインの影響を除外することが推奨されています。
次に、このベースラインを調整する解析方法について紹介します。
2.6 ANCOVAとは?
介入前の測定値 (ベースライン) が、介入後の変化量に影響している場合、単純に変化量だけを群間で比較すると、公平な比較にならないことがあります。
ベースラインを調整する解析は、共分散分析、通称ANCOVA (アンコバ) と呼びます。
| 共分散分析 (analysis of covariance; ANCOVA) |
|---|
| 分散分析に対して回帰分析を応用することで共変量 (目的のデータに影響を与えると考えられるデータ) の影響を考慮し、目的のデータを総合的に群間比較する解析方法である。 |
ANCOVAは、分散分析に回帰分析の原理を応用することで共変量と呼ばれる目的変数に影響を与えるデータの影響を排除して解析する統計解析手法です。
ANCOVA は、
- 群の違い (介入効果)
- 介入前の測定値など、結果に影響を与える要因 (共変量)
を同時にモデル化し、共変量の影響を統計的に取り除いたうえで群間比較を行う手法です。
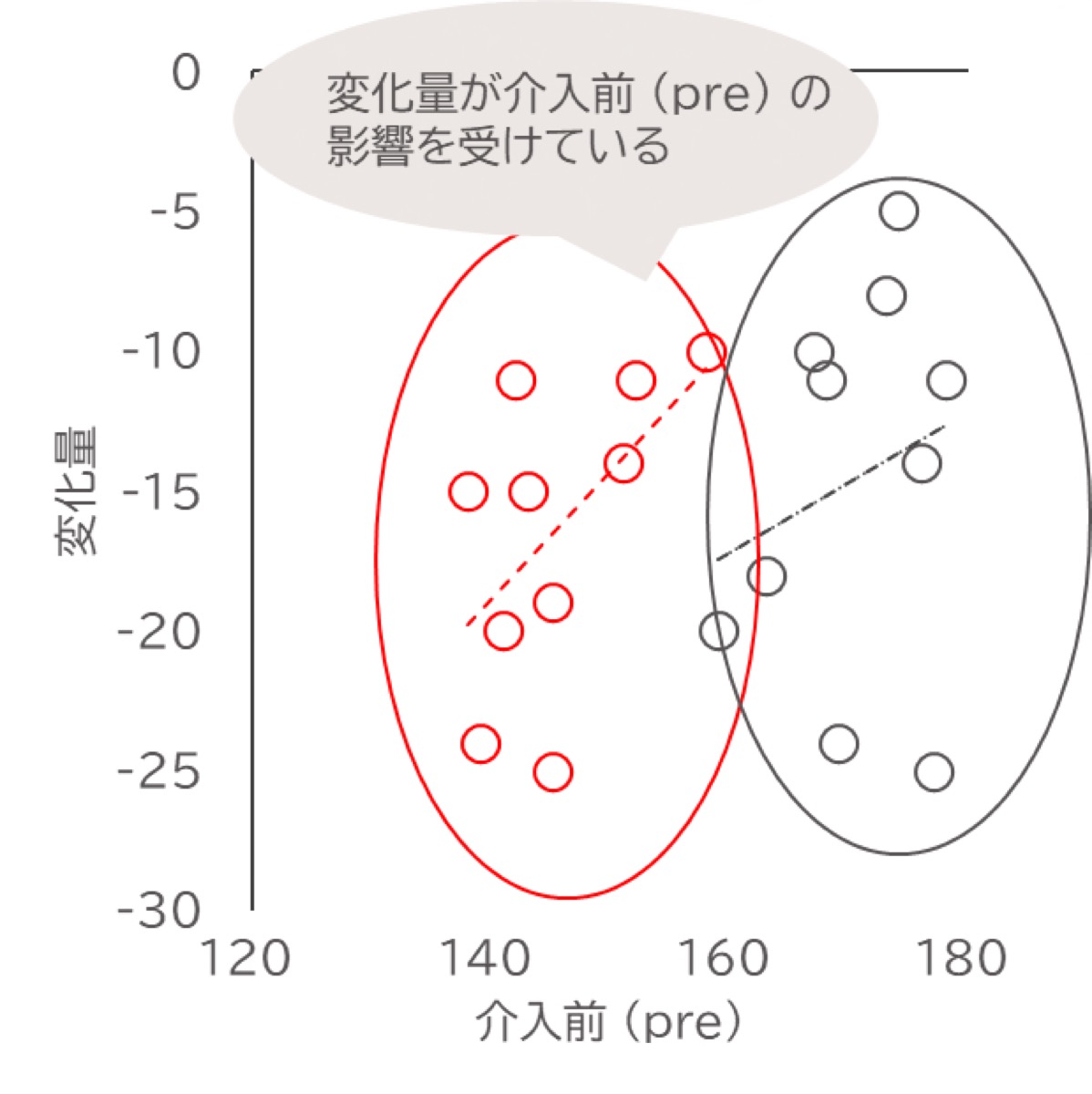
上記にベースラインが異なる2つの介入群の、介入前の測定値 (ベースライン) と変化量の相関図を示しました。
図のようにベースラインが大きいほど、変化量も大きくなっている場合、変化量がベースラインの影響を受けている可能性があると考えられます。
この状態で単純に変化量をt検定等で群間比較すると、観察された差が「介入の効果」なのか、「もともとのベースラインの違い」なのかが判別できず、比較可能性が疑われることになります。
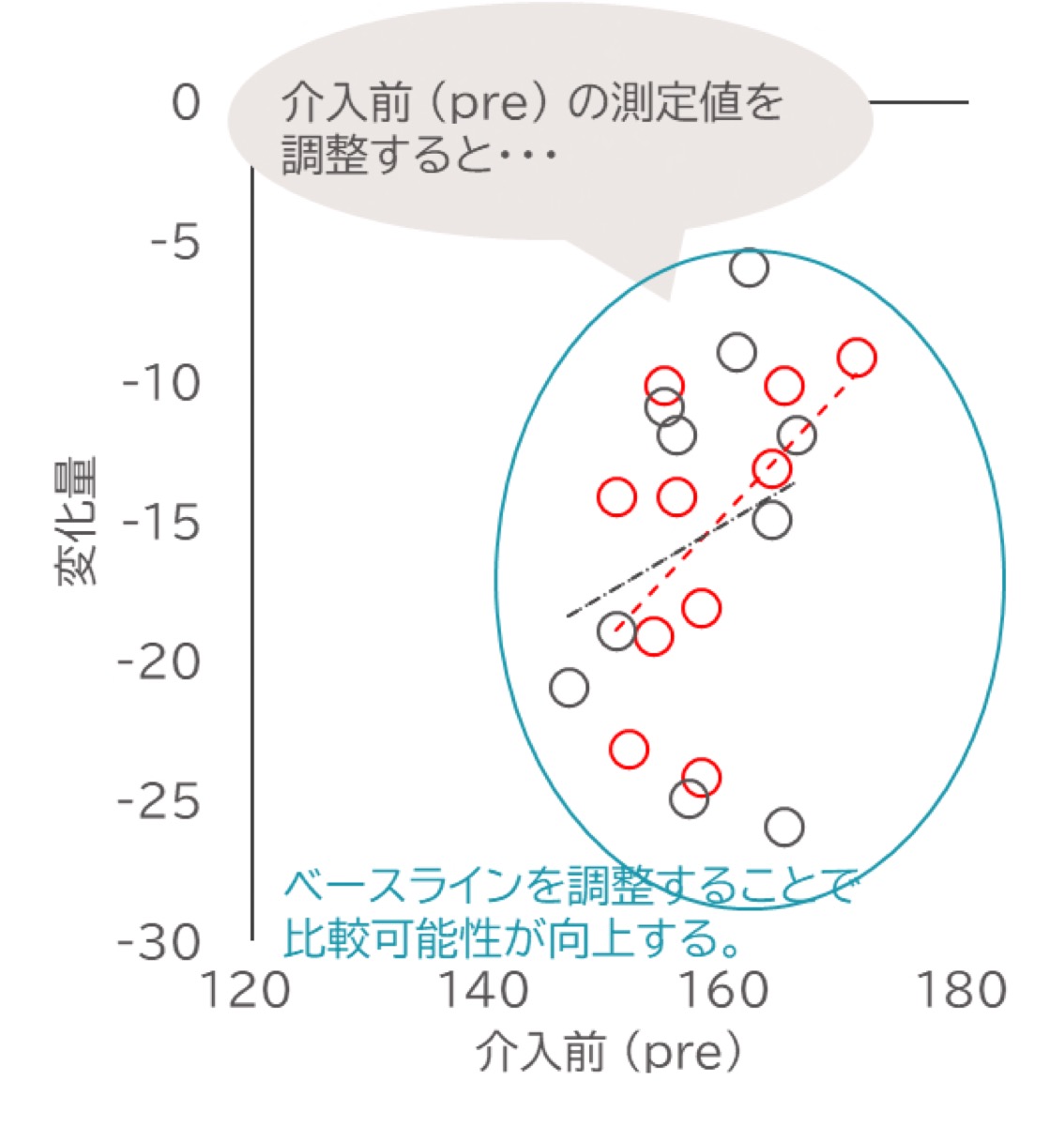
しかし、上記の図のようにベースラインを共変量として調整すると、「もし2群のベースラインが均等だったとしたら」、「その条件下で、変化量は群間でどう違うか」を統計モデル上で評価できます。
この調節によって、介入前の測定値の影響を排除して介入そのものによる差に焦点を当てた比較を行い、変化量の比較可能性を向上させることができます。
図中で点が揃って見えるのは、調整後はベースラインの値が揃い、群間の比較条件が揃ったことを視覚的に示しています。
解析データセットの準備
3.1 使用する解析データセット
解析データセットは、tidyCDISCパッケージに含まれるadlbcを使用します。adlbcは、Analysis Data Model (ADaM) 形式に従った臨床検査データです。
3.2 ADaMデータとは?
ADaM (Analysis Data Model) データは、臨床試験で得られた各種データを、統計解析に直接利用できる形へと整理・加工した解析用データセットを指します。CDISC (Clinical Data Interchange Standards Consortium) が定める標準の一つであり、主に規制当局への申請や結果報告を想定して設計されています。
臨床試験では、被験者背景、検査値、有害事象など、多岐にわたるデータが収集されます。これらはまずSDTMと呼ばれる形式で標準化されますが、SDTMは「何が、いつ、どのように測定されたか」を記録することに重点が置かれており、そのままでは必ずしも解析に適した構造とはなっていません。ADaMは、こうしたSDTMデータを基に、解析目的に沿って再構成されたデータである点に特徴があります。
ADaMでは、「1レコードが何を意味するのか」が明確に定義されます。一般的には、被験者 × 解析項目 × 時点といった単位でレコードが構成され、解析に必要な値や派生変数があらかじめ計算された状態で格納されます。これにより、統計解析プログラムは比較的単純な記述で済み、解析結果の再現性や追跡可能性が担保されます。
このようにADaMは、単なるデータ整形ではなく、「どのような前提で、どの集団を、どの指標で評価するのか」という解析思想をデータ構造として明示化する役割を担っています。そのため、解析結果を第三者が確認した際にも、データと解析手順の関係を理解しやすいという利点があります。
3.3 adlbcデータセットとは?
ADaMの中でも、検査値やバイタルサインなどの連続量データを扱う際によく用いられるのが、BDS (Basic Data Structure) と呼ばれる基本構造です。BDSでは、PARAM (解析項目) や AVISIT (解析用Visit) といった共通の変数群を用いることで、異なる項目であっても統一的な解析が可能になります。
adlbcデータセットは、その代表例の一つであり、臨床検査値 (Laboratory Test) を解析するためのADaMデータセットです。ここでは、各検査項目がPARAMとして整理され、解析に使用する値 (AVAL)、ベースライン値 (BASE)、ベースラインからの変化量 (CHG) などが一つのデータセット内にまとめられています。
この構造の利点は、解析者が「どの検査項目か」「どの時点か」を意識しながら、同一の解析コードを複数項目に適用できる点にあります。例えば、ALTやAST、LDLコレステロールといった異なる検査値であっても、PARAMを切り替えるだけで同様の解析を実行することが可能です。これは、解析の一貫性を保つ上で非常に重要な特性といえます。
一方で、BDS構造は縦長のデータ形式となるため、初学者にとっては直感的に理解しづらい場合もあります。しかし、解析対象が増えたり、評価時点が複雑になったりするほど、その設計思想の有用性が明確になってきます。
3.4 解析データセットのダウンロード
tidyCDISCをインストールして、データセットを取得します。
# 必要なパッケージのインストールと読み込み
install.packages("tidyCDISC")
library(tidyCDISC)
# データの読み込み
data("adlbc")
dat <- adlbc3.5 構成を確認する
解析データセットの中身の確認をしていきたいのですが、
> ncol(dat)
[1] 46列数が多いので、主要な部分だけ説明します。
| SUBJID | Subject Identifier for the Study |
|---|---|
| USUBJID | Unique Subject Identifier |
| TRTP | Planned Treatment |
| TRTPN | Planned Treatment (N) |
| TRTA | Actual Treatment |
| TRTAN | Actual Treatment (N) |
| SAFFL | Safety Population Flag |
| AVISIT | Analysis Visit |
| AVISITN | Analysis Visit (N) |
| VISIT | Visit Name |
| VISITNUM | Visit Number |
| PARAM | Parameter |
| AVAL | Analysis Value |
| BASE | Baseline Value |
| CHG | Change from Baseline |
1行が「被験者 × 項目 (PARAM) × 時点 (AVISIT)」を表す、縦持ち構造の解析用データです。
-
- SUBJID / USUBJID
- SUBJID (Subject Identifier for the Study) は、試験内で付与される被験者番号を表します。一方、USUBJID (Unique Subject Identifier) は、試験間を通じて一意となる被験者識別子であり、通常は試験IDとSUBJIDを組み合わせた形式で定義されます。
解析実務においては、ADaMでは原則としてUSUBJID が主キーとして用いられます。SUBJIDは表示用や参照用として残されることが多く、解析ロジック自体はUSUBJIDを基準に構築されます。
-
- TRTP / TRTPN
-
TRTP (Planned Treatment) は、割付計画上で被験者に予定されていた治療群を示します。TRTPNはその数値コードであり、群間比較やソート処理を行う際に用いられます。
ランダム化に基づく解析や、ITT集団での評価では、このPlanned Treatmentが解析群定義の基礎となることが一般的です。
-
- TRTA / TRTAN
-
TRTA (Actual Treatment) は、被験者が実際に受けた治療内容を表します。TRTAN はその数値表現です。
実投与に基づく解析 (Safety解析など) では、TRTA が主要な群分け変数として使用されます。TRTPとTRTAが一致しないケースは、プロトコル逸脱や治療変更の有無を検討する際の重要な手がかりとなります。
-
- SAFFL
-
SAFFL (Safety Population Flag) は、安全性解析対象集団に含まれるかどうかを示すフラグです。「Y」が付与された被験者が解析対象となります。
ADaMでは、このような解析集団フラグが明示的に変数として保持されており、解析時に WHERE句やFILTERで簡潔に集団を定義できます。
ADaMでは、中止理由をこのようなフラグとして明示的に管理することで、欠測データの背景整理や安全性の解釈を解析段階で反映しやすくなります。主解析で直接使用されない場合でも、結果解釈や補足解析において重要な情報となる変数です。
-
- VISIT / VISITNUM
-
VISIT は、CRF 上で定義された Visit 名称を表し、VISITNUMはその数値コードです。実施順序の管理や時系列の把握には、VISITNUMが用いられます。
これらは、データ収集上のVisitを反映したものであり、必ずしも解析用の時点と一致するとは限りません。
-
- AVISIT / AVISITN
-
AVISIT (Analysis Visit) は、解析のために再定義された Visit名を示します。AVISITNはその数値コードです。
例えば、複数の測定日をまとめて「Week 4」として扱う場合など、解析上の判断が反映されます。BDS構造では、AVISITが解析の軸となるVisit変数であり、VISITよりも優先して使用されるのが一般的です。
-
- PARAM
-
PARAM (Parameter) は、解析対象となる項目名を表します。臨床検査値であれば、ALT、AST、LDL-C などが該当します。
BDS データセットでは、異なる項目を縦に積み上げて管理するため、PARAM が「何を解析しているのか」を特定する重要な変数となります。
-
- AVAL
-
AVAL (Analysis Value) は、解析に実際に使用される数値です。単位換算、代表値の選択、欠測処理などを経た後の「最終的な解析値」が格納されます。統計解析でモデルに投入されるのは、原則としてこのAVALです。
-
- BASE
-
BASE (Baseline Value) は、各 PARAMに対して定義されたベースライン値を示します。通常は、治療開始前の最後の観測値が用いられます。ベースラインの定義は解析結果に大きく影響するため、ADaMでは明示的に変数として保持されています。
-
- CHG
-
CHG (Change from Baseline) は、AVAL と BASE の差分として計算された変化量を表します。
ADaMでは、こうした派生指標を事前に計算しておくことで、解析プログラムを簡潔かつ一貫したものにしています。
3.6 実際の解析に使用する変数
ADaMデータセットには多くの変数が含まれていますが、統計解析で直接使用されるものは以下の変数などに限られています。
| 分類 | 変数名 | 役割 |
|---|---|---|
| 被験者 | USUBJID | 被験者の一意識別子 |
| 解析集団 | SAFFL | 解析対象者の抽出条件 |
| 治療群 | TRTA | 群間比較の主要変数 |
| 治療群 | TRTAN | 数値コード(処理用) |
| 解析時点 | AVISIT | 解析用 Visit |
| 解析時点 | AVISITN | Visit の数値表現 |
| 解析項目 | PARAM | 解析対象項目 |
| 解析値 | AVAL | 実測値解析に使用 |
| ベースライン | BASE | 共変量として使用 |
| 変化量 | CHG | 有効性評価の指標 |
解析
スクリプト
================================================
# ANCOVA
# ================================================
library(tidyCDISC)
library(dplyr)
library(emmeans)
library(openxlsx)
options(contrasts = c("contr.treatment", "contr.poly"))
# -------------------------------
# User settings
# -------------------------------
ANALYSIS_FLAG <- "SAFFL"
GROUP_VAR <- "TRTA"
CONTROL_GROUP <- "Placebo"
ACTIVE_GROUP <- "Xanomeline High Dose"
COVARIATE_VAR <- "BASE"
RESPONSE_VARS <- c("AVAL", "CHG")
PARAM_VAR <- "PARAM"
VISIT_VAR <- "AVISIT"
VISITN_VAR <- "AVISITN"
FINAL_VISITN <- 26
desktop_path <- file.path(Sys.getenv("USERPROFILE"), "Desktop")
# -------------------------------
# Data preparation
# -------------------------------
data(adlbc, package = "tidyCDISC")
df <- adlbc %>%
filter(
.data[[ANALYSIS_FLAG]] == "Y",
.data[[GROUP_VAR]] %in% c(CONTROL_GROUP, ACTIVE_GROUP),
.data[[VISITN_VAR]] == FINAL_VISITN,
!is.na(.data[[COVARIATE_VAR]])
) %>%
mutate(
!!GROUP_VAR := factor(
.data[[GROUP_VAR]],
levels = c(CONTROL_GROUP, ACTIVE_GROUP)
)
)
stopifnot(nrow(df) > 0)
# -------------------------------
# ANCOVA function (AVAL / CHG 両対応)
# -------------------------------
get1 <- function(x) if (length(x) == 1) x else NA
run_ancova <- function(df) {
out <- list()
for (resp in RESPONSE_VARS) {
for (p in unique(df[[PARAM_VAR]])) {
for (v in unique(df[[VISIT_VAR]])) {
d <- df %>%
filter(
.data[[PARAM_VAR]] == p,
.data[[VISIT_VAR]] == v,
!is.na(.data[[resp]])
)
if (nrow(d) < 3) next
fit <- lm(
reformulate(c(GROUP_VAR, COVARIATE_VAR), resp),
data = d
)
emm <- emmeans(fit, specs = GROUP_VAR)
emm_df <- as.data.frame(summary(emm, infer = TRUE))
diff_df <- as.data.frame(
summary(
contrast(emm, method = "revpairwise", adjust = "none"),
infer = TRUE
)
)
out[[length(out) + 1]] <- data.frame(
AnalysisType = resp,
Variable = p,
VISIT = as.character(v),
GROUP1 = CONTROL_GROUP,
GROUP2 = ACTIVE_GROUP,
GROUP1_N = sum(d[[GROUP_VAR]] == CONTROL_GROUP),
GROUP2_N = sum(d[[GROUP_VAR]] == ACTIVE_GROUP),
GROUP1_emmean = get1(emm_df$emmean[emm_df[[GROUP_VAR]] == CONTROL_GROUP]),
GROUP1_SE = get1(emm_df$SE[emm_df[[GROUP_VAR]] == CONTROL_GROUP]),
GROUP1_lower.CL = get1(emm_df$lower.CL[emm_df[[GROUP_VAR]] == CONTROL_GROUP]),
GROUP1_upper.CL = get1(emm_df$upper.CL[emm_df[[GROUP_VAR]] == CONTROL_GROUP]),
GROUP2_emmean = get1(emm_df$emmean[emm_df[[GROUP_VAR]] == ACTIVE_GROUP]),
GROUP2_SE = get1(emm_df$SE[emm_df[[GROUP_VAR]] == ACTIVE_GROUP]),
GROUP2_lower.CL = get1(emm_df$lower.CL[emm_df[[GROUP_VAR]] == ACTIVE_GROUP]),
GROUP2_upper.CL = get1(emm_df$upper.CL[emm_df[[GROUP_VAR]] == ACTIVE_GROUP]),
Diff_estimate = get1(diff_df$estimate),
Diff_SE = get1(diff_df$SE),
Diff_lower.CL = get1(diff_df$lower.CL),
Diff_upper.CL = get1(diff_df$upper.CL),
Diff_p.value = get1(diff_df$p.value),
stringsAsFactors = FALSE
)
}
}
}
bind_rows(out)
}
# -------------------------------
# Run analysis
# -------------------------------
result_df <- run_ancova(df)
stopifnot(nrow(result_df) > 0)
# -------------------------------
# Excel output
# -------------------------------
wb <- createWorkbook()
addWorksheet(wb, "ANCOVA_Results")
writeData(wb, "ANCOVA_Results", result_df)
addWorksheet(wb, "Settings")
writeData(
wb, "Settings",
data.frame(
Setting = c(
"Analysis Flag",
"Group Variable",
"Control Group",
"Active Group",
"Covariate",
"Response Variables",
"Final Visit"
),
Value = c(
ANALYSIS_FLAG,
GROUP_VAR,
CONTROL_GROUP,
ACTIVE_GROUP,
COVARIATE_VAR,
paste(RESPONSE_VARS, collapse = ", "),
FINAL_VISITN
)
)
)
saveWorkbook(
wb,
file.path(desktop_path, "ANCOVA.xlsx"),
overwrite = TRUE
)4.1 ライブラリ
使用するパッケージは以下の通りです:
library(tidyCDISC)
library(dplyr)
library(emmeans)
library(openxlsx)
options(contrasts = c("contr.treatment", "contr.poly"))本スクリプトでは、主に上記の4つのパッケージを利用しています。
それぞれの役割は以下の通りです。
-
- tidyCDISC パッケージ
- tidyCDISC は、CDISC標準(特にADaM)に準拠した解析用データセットを、Rで扱いやすい形で提供することを目的としたパッケージです。
-
- dplyr パッケージ
- dplyr は、データフレーム操作を簡潔に記述するためのパッケージです。
-
- emmeans パッケージ
- emmeans(Estimated Marginal Means)は、線形モデルや分散分析モデルから調整平均(LS mean)および群間差を算出するためのパッケージです。
-
- openxlsx パッケージ
- openxlsx は、Excelファイル(.xlsx)をRから直接読み書きするためのパッケージです。
-
- options(contrasts = c("contr.treatment", "contr.poly"))
- この設定は、線形モデルにおける因子変数の扱い方を指定するものです。1つ目の引数 contr.treatmentは、順序のない因子変数 (治療群など) に対するコントラストの設定です。処理対比では、第1水準を参照カテゴリ (基準) とし、他の水準をそれとの差として表現します。
4.2 設定
# -------------------------------
# Settings
# -------------------------------
ANALYSIS_FLAG <- "SAFFL"
GROUP_VAR <- "TRTA"
CONTROL_GROUP <- "Placebo"
ACTIVE_GROUP <- "Xanomeline High Dose"
COVARIATE_VAR <- "BASE"
RESPONSE_VARS <- c("AVAL", "CHG")
PARAM_VAR <- "PARAM"
VISIT_VAR <- "AVISIT"
VISITN_VAR <- "AVISITN"
FINAL_VISITN <- 26
desktop_path <- file.path(Sys.getenv("USERPROFILE"), "Desktop")この部分は、本スクリプトにおける解析条件および解析対象の定義を一括して指定しています。
解析対象集団フラグ(ANALYSIS_FLAG)
ANALYSIS_FLAG <- "SAFFL"解析対象とする集団を指定するフラグ変数です。
ここではSAFFL (Safety Population Flag) を用いており、安全性解析対象集団に該当する症例のみを解析に含めます。この指定により、意図しない症例の混入を防ぎ、解析対象集団を明確に定義しています。
群変数および比較群の定義
GROUP_VAR <- "TRTA"
CONTROL_GROUP <- "Placebo"
ACTIVE_GROUP <- "Xanomeline High Dose"GROUP_VARには、治療群を表す変数名を指定します。
本例ではTRTAを用いており、割り付けられた治療内容に基づく群分けを行います。
また、比較対象となる2群を以下のように明示的に指定しています。
- CONTROL_GROUP: 対照群 (Placebo)
- ACTIVE_GROUP: 実薬群 (Xanomeline High Dose)
このように群名を明示することで、解析対象を常に2群に限定し、解析結果の解釈を一貫したものにしています。
共変量および評価変数の指定
COVARIATE_VAR <- "BASE"
RESPONSE_VARS <- c("AVAL", "CHG")COVARIATE_VARには、共変量としてモデルに組み込む変数を指定します。
ここではベースライン値を表すBASEを用いています。
RESPONSE_VARS には、解析対象とする評価変数をベクトルとして指定しています。
- AVAL: 評価時点の実測値
- CHG: ベースラインからの変化量
これにより、実測値解析と変化量解析を同一の枠組みで実行できるようになっています。
パラメータおよび時点の指定
PARAM_VAR <- "PARAM"
VISIT_VAR <- "AVISIT"
VISITN_VAR <- "AVISITN"
FINAL_VISITN <- 26PARAM_VARは、解析対象となる評価項目 (検査項目など) を表す変数です。解析はこの変数ごとに独立して実行されます。
VISIT_VARおよびVISITN_VAR は、評価が行われた時点を表します。そのうち FINAL_VISITNで指定した値 (ここでは26) に該当する時点のみを解析対象とし、最終評価時点に限定した解析を行います。
出力先フォルダの指定
desktop_path <- file.path(Sys.getenv("USERPROFILE"), "Desktop")解析結果を出力するフォルダとして、ユーザーのデスクトップを指定しています。
これにより、解析終了後に結果ファイルを容易に確認できるようになっています。
4.3 データ前処理
# -------------------------------
# Data preparation
# -------------------------------
data(adlbc, package = "tidyCDISC")
df <- adlbc %>%
filter(
.data[[ANALYSIS_FLAG]] == "Y",
.data[[GROUP_VAR]] %in% c(CONTROL_GROUP, ACTIVE_GROUP),
.data[[VISITN_VAR]] == FINAL_VISITN,
!is.na(.data[[COVARIATE_VAR]])
) %>%
mutate(
!!GROUP_VAR := factor(
.data[[GROUP_VAR]],
levels = c(CONTROL_GROUP, ACTIVE_GROUP)
)
)
stopifnot(nrow(df) > 0)この部分では、解析に使用するデータセットの読み込みおよび前処理を行っています。解析の妥当性を確保するため、不要な症例や条件に合致しない観測値を事前に除外し、解析に適した形へと整形します。
データセットの読み込み
data(adlbc, package = "tidyCDISC")tidyCDISC パッケージに含まれる adlbcデータセットを読み込みます。
adlbcはADaM形式に準拠した検査値データセットであり、
- 被験者情報
- 治療群
- ベースライン値
- 各時点での測定値
など、共分散分析に必要な情報が一通り含まれています。
解析対象データの抽出 (filter)
df <- adlbc %>%
filter(
.data[[ANALYSIS_FLAG]] == "Y",
.data[[GROUP_VAR]] %in% c(CONTROL_GROUP, ACTIVE_GROUP),
.data[[VISITN_VAR]] == FINAL_VISITN,
!is.na(.data[[COVARIATE_VAR]])
)
ここでは、解析に必要な条件を満たすデータのみを抽出しています。
主な条件は以下のとおりです。
-
- ANALYSIS_FLAG == "Y"
- 解析対象集団に含まれる症例のみを使用
-
- GROUP_VAR が対照群または実薬群に該当
- 指定した2群以外の症例を除外
-
- VISITN_VAR == FINAL_VISITN
- 最終評価時点の測定値のみを解析対象とする
-
- COVARIATE_VAR (ベースライン値) が欠損していない
- 共変量を含むモデル推定が可能なデータに限定
これにより、解析モデルに不要なデータや不完全な観測値を事前に除外しています。
群変数の因子化と水準の固定
mutate(
!!GROUP_VAR := factor(
.data[[GROUP_VAR]],
levels = c(CONTROL_GROUP, ACTIVE_GROUP)
)
)
治療群変数を因子 (factor) に変換し、水準の順序を明示的に指定しています。
- 第1水準: 対照群
- 第2水準: 実薬群
この処理により、後続のモデル推定や群間差の算出において、「どちらを基準とした比較なのか」が常に一貫した形で定義されます。
4.4 ANCOVA関数の定義
# -------------------------------
# ANCOVA function
# -------------------------------
get1 <- function(x) if (length(x) == 1) x else NA
run_ancova <- function(df) {
out <- list()
for (resp in RESPONSE_VARS) {
for (p in unique(df[[PARAM_VAR]])) {
for (v in unique(df[[VISIT_VAR]])) {
d <- df %>%
filter(
.data[[PARAM_VAR]] == p,
.data[[VISIT_VAR]] == v,
!is.na(.data[[resp]])
)
if (nrow(d) < 3) next
fit <- lm(
reformulate(c(GROUP_VAR, COVARIATE_VAR), resp),
data = d
)
emm <- emmeans(fit, specs = GROUP_VAR)
emm_df <- as.data.frame(summary(emm, infer = TRUE))
diff_df <- as.data.frame(
summary(
contrast(emm, method = "revpairwise", adjust = "none"),
infer = TRUE
)
)
out[[length(out) + 1]] <- data.frame(
AnalysisType = resp,
Variable = p,
VISIT = as.character(v),
GROUP1 = CONTROL_GROUP,
GROUP2 = ACTIVE_GROUP,
GROUP1_N = sum(d[[GROUP_VAR]] == CONTROL_GROUP),
GROUP2_N = sum(d[[GROUP_VAR]] == ACTIVE_GROUP),
GROUP1_emmean = get1(emm_df$emmean[emm_df[[GROUP_VAR]] == CONTROL_GROUP]),
GROUP1_SE = get1(emm_df$SE[emm_df[[GROUP_VAR]] == CONTROL_GROUP]),
GROUP1_lower.CL = get1(emm_df$lower.CL[emm_df[[GROUP_VAR]] == CONTROL_GROUP]),
GROUP1_upper.CL = get1(emm_df$upper.CL[emm_df[[GROUP_VAR]] == CONTROL_GROUP]),
GROUP2_emmean = get1(emm_df$emmean[emm_df[[GROUP_VAR]] == ACTIVE_GROUP]),
GROUP2_SE = get1(emm_df$SE[emm_df[[GROUP_VAR]] == ACTIVE_GROUP]),
GROUP2_lower.CL = get1(emm_df$lower.CL[emm_df[[GROUP_VAR]] == ACTIVE_GROUP]),
GROUP2_upper.CL = get1(emm_df$upper.CL[emm_df[[GROUP_VAR]] == ACTIVE_GROUP]),
Diff_estimate = get1(diff_df$estimate),
Diff_SE = get1(diff_df$SE),
Diff_lower.CL = get1(diff_df$lower.CL),
Diff_upper.CL = get1(diff_df$upper.CL),
Diff_p.value = get1(diff_df$p.value),
stringsAsFactors = FALSE
)
}
}
}
bind_rows(out)
}ANCOVA
get1 <- function(x) if (length(x) == 1) x else NAまず、補助関数get1() を定義しています。この関数は、長さが1の値のみをそのまま返し、それ以外の場合にはNAを返します。
共分散分析の結果をデータフレームとしてまとめる際、想定外に複数の値が返された場合でも処理が停止しないよう、安全装置として機能します。
run_ancova <- function(df) {run_ancova() は、本スクリプトの中核となる解析関数です。前処理済みのデータフレームを入力として受け取り、評価項目・時点・評価指標ごとに共分散分析を実行します。
結果格納用オブジェクトの初期化
out <- list()各解析結果を一時的に格納するためのリストを初期化します。最終的には、このリストを結合して1つの結果データフレームを作成します。
評価指標・項目・時点ごとのループ処理
for (resp in RESPONSE_VARS) {
for (p in unique(df[[PARAM_VAR]])) {
for (v in unique(df[[VISIT_VAR]])) {
ここでは三重のループ構造を用いて、以下の組み合わせごとに解析を行います。
- resp: 評価指標 (実測値AVAL、変化量CHG)
- p: 評価項目 (検査項目など)
- v: 時点
これにより、すべての評価指標 × 評価項目 × 時点について、同一の解析手順を自動的に適用できます。
対象データの抽出と欠損除外
d <- df %>%
filter(
.data[[PARAM_VAR]] == p,
.data[[VISIT_VAR]] == v,
!is.na(.data[[resp]])
)
現在の解析対象に対応するデータのみを抽出しています。あわせて、評価指標 (AVALまたはCHG) が欠損している観測値は除外しています。
共分散分析モデルの推定
fit <- lm(
reformulate(c(GROUP_VAR, COVARIATE_VAR), resp),
data = d
)線形モデルを用いて共分散分析を実行します。
- 目的変数: 評価指標 (AVALまたはCHG)
- 説明変数: 治療群
- 共変量: ベースライン値
reformulate() を用いることで、変数名を文字列として柔軟に指定できる構造になっています。
調整平均値 (推定周辺平均) の算出
emm <- emmeans(fit, specs = GROUP_VAR)
emm_df <- as.data.frame(summary(emm, infer = TRUE))推定したモデルから、治療群ごとの調整平均値を算出します。共変量は平均値に固定され、群間の比較が行いやすい形に整理されます。
群間差の算出
diff_df <- as.data.frame(
summary(
contrast(emm, method = "revpairwise", adjust = "none"),
infer = TRUE
)
)2群間の差 (実薬群 − 対照群) を算出します。ここでは多重性補正を行わず、推定値・標準誤差・信頼区間・p値を取得します。
結果の整理と保存
out[[length(out) + 1]] <- data.frame(
AnalysisType = resp,
Variable = p,
VISIT = as.character(v),
...
)各解析結果を1行のデータフレームとして整理し、リストに格納します。
- AnalysisType:評価指標 (AVAL / CHG)
- 群ごとの症例数
- 調整平均値および信頼区間
- 群間差およびその統計量
この形式により、後続の出力処理や結果確認が容易になります。
結果の結合
bind_rows(out)
}リストに格納されたすべての解析結果を結合し、1つのデータフレームとして返します。
以上の処理で解析の手順をまとめています。
この後に、関数を呼び出さないと解析は実行されません。
4.5 ANCOVA実行
# -------------------------------
# Run analysis
# -------------------------------
result_df <- run_ancova(df)
stopifnot(nrow(result_df) > 0)
ここでは、前段で定義した run_ancova() 関数を実行しています。前処理済みの解析データセット df を入力として渡すことで、
- 指標 (AVAL、CHG)
- 評価項目 (PARAM)
- 時点 (AVISIT)
のすべての組み合わせに対して共分散分析が自動的に実行され、解析結果が1つのデータフレームとしてresult_dfに格納されます。
この時点でresult_dfには、群ごとの調整平均値、群間差、信頼区間、p値など、以降の結果確認や出力に必要な情報がすべて整理された形で含まれています。
4.6 解析結果のExcel出力
# -------------------------------
# Excel output
# -------------------------------
wb <- createWorkbook()
addWorksheet(wb, "ANCOVA_Results")
writeData(wb, "ANCOVA_Results", result_df)
addWorksheet(wb, "Settings")
writeData(
wb, "Settings",
data.frame(
Setting = c(
"Analysis Flag",
"Group Variable",
"Control Group",
"Active Group",
"Covariate",
"Response Variables",
"Final Visit"
),
Value = c(
ANALYSIS_FLAG,
GROUP_VAR,
CONTROL_GROUP,
ACTIVE_GROUP,
COVARIATE_VAR,
paste(RESPONSE_VARS, collapse = ", "),
FINAL_VISITN
)
)
)
saveWorkbook(
wb,
file.path(desktop_path, "ANCOVA.xlsx"),
overwrite = TRUE
)ここでは、解析結果をExcelファイルとして保存するための準備を行います。
createWorkbook() により、空のExcelワークブックを1つ作成し、以降の処理でこのワークブックに複数のシートを追加していきます。
ANCOVA 結果シートの作成
addWorksheet(wb, "ANCOVA_Results")
writeData(wb, "ANCOVA_Results", result_df)最初に、共分散分析の結果を格納するためのシートANCOVA_Resultsを作成します。このシートが、解析結果の本体に相当します。
設定情報シートの作成
addWorksheet(wb, "Settings")
writeData(
wb, "Settings",
data.frame(
Setting = c(
"Analysis Flag",
"Group Variable",
"Control Group",
"Active Group",
"Covariate",
"Response Variables",
"Final Visit"
),
Value = c(
ANALYSIS_FLAG,
GROUP_VAR,
CONTROL_GROUP,
ACTIVE_GROUP,
COVARIATE_VAR,
paste(RESPONSE_VARS, collapse = ", "),
FINAL_VISITN
)
)
)次に、解析条件を記録するためのSettingsシートを作成します。
設定情報シートの作成
saveWorkbook(
wb,
file.path(desktop_path, "ANCOVA.xlsx"),
overwrite = TRUE
)最後に、作成したワークブックをExcelファイルとして保存します。
まとめ
本稿では、変化量 (change from baseline) を用いた群間比較が、ベースラインの影響を受けることで比較可能性を損ない得る点を整理し、その対応として ベースライン調整 (ANCOVA) が実務上重要であることを解説しました。変化量は「分かりやすい」一方で、前値が異なる集団をそのまま比較すると、介入効果の推定にバイアスが入りやすいことを、回帰の観点から確認しました。
そのうえで、ベースラインを共変量としてモデルに組み込むことで、「もし両群のベースラインが同等だったとしたら、その条件下で群間差はどうなるか」を推定でき、介入効果をより公平かつ精度高く評価できることを示しました。さらに、EMAのベースライン調整に関する考え方とも整合する点を踏まえ、適切に調整するなら、AVAL解析とCHG解析で治療効果推定が一致し得るという実務上の重要ポイントにも触れました。
実装面では、tidyCDISC::adlbc (ADaM/BDS形式) を用い、Rで
- 解析集団フラグによる抽出
- 2群比較 (Placebo vs Active) の固定
- 最終Visitに限定した解析
- lm() + emmeans による調整平均と群間差の算出
- 結果のExcel出力 (Settings含む)
までを一連のワークフローとして提示しました。BDS構造の利点を活かし、検査項目 (PARAM) が増えても同じコードで横展開できるため、ヒト臨床試験 (ヒト試験) や機能性表示食品の解析実務において、一貫性のある解析結果の作成・説明・再現にそのまま応用できます。
次回 (2) では、ANCOVAを使う際に実務で迷いやすいポイント――たとえば 交互作用 (群×ベースライン) の扱い、外れ値・分布の歪みへの対応などの前提条件の確認方法を、同じデータ構造を前提に整理していきます。
関連するサービス

参考文献
- ASCON科学者委員会. 機能性表示食品の効果判定に関する新たな項目の設定について. 2019 [Internet]. [cited 2026 Feb 7]. Available from: http://ascon.bz/archives/678
- ASCON科学者委員会. 健康産業流通新聞 (H31.3.7付) の報道について. 2019 [Internet]. [cited 2026 Feb 7]. Available from: http://ascon.bz/archives/687
- ASCON科学者委員会. 機能性表示食品に対する食品表示等関係法令に基づく事後的規制 (事後チェック) の透明性の確保等に関する指針 (案) に関するパブリックコメント. 2020 [Internet]. [cited 2026 Feb 7]. Available from: http://ascon.bz/archives/756
- ASCON科学者委員会. 機能性表示食品の評価判定基準 (2020年6月改定・8/1微修正). 2020 [Internet]. [cited 2026 Feb 7]. Available from: http://ascon.bz/archives/816
- 厚生労働省. ICH E9 臨床試験のための統計的原則 (平成10年11月30日付 医薬審第1047号). 1998 [Internet]. [cited 2026 Feb 7]. Available from: https://www.pmda.go.jp/files/000156112.pdf
- European Medicines Agency. Guideline on adjustment for baseline covariates in clinical trials. 2013 [Internet]. [cited 2026 Feb 7]. Available from: https://www.ema.europa.eu/en/documents/scientific-guideline/guideline-adjustment-baseline-covariates-clinical-trials_en.pdf
- Frison L, Pocock SJ. Repeated measures in clinical trials: analysis using mean summary statistics and its implications for design. Stat Med. 1992;11(13):1685-1704. PMID: 1485053.
- 消費者庁. 機能性表示食品制度における臨床試験及び安全性の評価内容の実態把握の検証・調査事業 報告書 (平成30年3月). 2018 [Internet]. [cited 2026 Feb 7]. Available from: https://www.caa.go.jp/policies/policy/food_labeling/information/research/2017/pdf/information_research_2017_180822_0001.pdf