臨床検査データを可視化するダッシュボードの作成

- アウトライン
-
- 作成日: 2025/12/8
- 更新日: –
はじめに
ヒト臨床試験 (ヒト試験) のデータを扱う業務において、臨床検査データ (血液や尿など) をどのように可視化し、効率的に品質評価や記述統計を実施するかは、統計解析担当者にとって重要なテーマです。
本稿は、Shinyを使って臨床検査データのダッシュボードを作成してみます。Shiny (シャイニー) とは、RでインタラクティブなWebアプリを作成できるフレームワークです。
- Web開発 (HTML/CSS/JavaScript) の知識が不要
- Rのコードだけで動的な可視化・表・アプリが作れる
- ローカルPCでもサーバーでも動作できる
という特徴があります。
詳しい機能などは、以下のページでチェックしてみてください。

データ品質の初期チェックを高速化したり、可視化・記述統計をリアルタイムで確認するなど、Shinyには様々な可能性があるので、本稿を通してヒントを得ていただけたら幸いです。
解析データセットの準備
2.1 使用する解析データセット
解析データセットは、tidyCDISCパッケージに含まれるadlbcを使用します。
adlbcは、Analysis Data Model (ADaM) 形式の従った臨床検査データなので、今回のテーマに適したデータセットだと思います。
2.2 解析データセットのダウンロード
tidyCDISCをインストールして、データセットを取得します。
# 必要なパッケージのインストールと読み込み
install.packages("tidyCDISC")
library(tidyCDISC)
# データの読み込み
data("adlbc")
dat <- adlbc
c2.3 構成を確認する
解析データセットの中身の確認をしていきたいのですが、
> ncol(dat)
[1] 46列数が多いので、主要な部分だけ説明します。
| SUBJID | Subject Identifier for the Study |
|---|---|
| USUBJID | Unique Subject Identifier |
| TRTP | Planned Treatment |
| TRTPN | Planned Treatment (N) |
| TRTA | Actual Treatment |
| TRTAN | Actual Treatment (N) |
| SAFFL | Safety Population Flag |
| AVISIT | Analysis Visit |
| AVISITN | Analysis Visit (N) |
| VISIT | Visit Name |
| VISITNUM | Visit Number |
| PARAM | Parameter |
| AVAL | Analysis Value |
| BASE | Baseline Value |
| CHG | Change from Baseline |
1行が「被験者 × 項目 (PARAM) × 時点 (AVISIT)」を表す、縦持ち構造の解析用データです。
この構造は、機能性表示食品や特定保健用食品のヒト臨床試験 (ヒト試験) でもよくあるデータ構造なので、すぐに業務に活かせると思います。
今回は、このデータセットを用いて、
- 群別平均推移 (Mean Profile)
- Visit × Treatment の分布 (Boxplot)
- 要約統計マトリックス (Summary Table)
の3種類の可視化を行ってみたいと思います。
それでは、臨床検査値ダッシュボードを開発していきましょう。
ダッシュボード開発
3.1 データセットの前処理
まず、Scheduled Visitsのみを解析対象にしましょう。
AVISITNを見ると、NAと99が存在することがわかります。
内容を確認すると、NAはUnscheduled、99はEnd of Treatment (EoT) なので、これらを除外することで、Visitの時系列解析が安定します。
# Unscheduled(AVISITN = NA)と EoT(AVISITN = 99)を除外し、
# Visit 情報を解析用に整形
dat_clean <- dat %>%
filter(!is.na(AVISITN)) %>% # Remove Unscheduled visits
filter(AVISITN != 99) %>% # Remove End of Treatment
mutate(
AVISITN = as.integer(AVISITN), # Visit 番号を整数化
AVISIT = as.character(AVISIT) # 文字列
) %>%
arrange(SUBJID, AVISITN)3.2 使用するパッケージ
使用するパッケージは以下の通りです:
library(shiny)
library(shinydashboard)
library(dplyr)
library(ggplot2)
library(tidyCDISC)Shinyは、冒頭で述べた通りRでWebアプリケーションを構築するためのフレームワークです。ダッシュボード全体の動的挙動を司る中心的パッケージであり、selectInput、plotOutput、renderPlot、reactive などすべてShinyの機能です。
Shinyがなければ、このアプリは単なる静的なRスクリプトとなり、インタラクティブな解析は実現できません。
Shinydashboardは、ShinyのUIを「ダッシュボード形式」に拡張するパッケージです。Header / Sidebar / Body の 3パネル構成を作成し、企業の業務システムのような見やすい画面が簡単に作れます。
dplyrは、tidyverse の中心パッケージであり、データハンドリングを行うための基本パッケージとして有名ですよね。今回、ADaMデータを使用するので、これがあると非常に加工が便利です。
ggplot2も有名なパッケージで、美しい図表を作成するためには欠かせません。
tidyCDISCは、CDISCのtidyデータを扱いやすくするパッケージであり、講習・実務向けサンプルのADaMデータセットが多数含まれます。そのため、データセットを取得するに使用します (2 解析データセットの準備 参照)。
3.3 UIを作成する
ShinydashboardパッケージでUIをデザインしていきます。このパッケージのdashboardPage() は shinydashboardのUI 全体 (Header、Sidebar、Body) を配置するためのレイアウトコンテナです。
まず、Headerを準備しましょう。
ヘッダーはダッシュボードの最上部に常に表示される部分で、
- アプリの名前
- ロゴ
- 通知アイコン
- ユーザー設定メニュー
などを置ける「ナビゲーションバー」の役割を持ちます。
今回は、titleパラメータだけを指定しており、画面左上にADLBC Explorerが大きく表示されます。
ui <- dashboardPage(
dashboardHeader(title = "ADLBC Explorer"),
dashboardSidebar(...),
dashboardBody(...)
)次にSidebarを準備します。
Shiny + shinydashboard における dashboardSidebar() は、ユーザーが操作を行う 入力 UI (Input Widgets) を配置する部分です。
今回は、Sidebarに以下の2つの操作を配置していきます:
- どの検査項目 (PARAM) を表示するか
- どの治療群 (TRTP) を比較に含めるか
コードは、以下の通りです。
dashboardSidebar(
selectInput(
inputId = "param",
label = "Select Laboratory Parameter:",
choices = unique(dat_clean$PARAM),
selected = unique(dat_clean$PARAM)[1]
),
checkboxGroupInput(
inputId = "groups",
label = "Select Treatment Groups:",
choices = unique(dat_clean$TRTP),
selected = unique(dat_clean$TRTP)
)
)ユーザーが選択した値はサーバー側ではinput$paramとして参照されます。
この値によって、Mean Profile、Boxplot、Summary Tableがすべて別の項目に切り替わる仕組みです。
label = "Select Laboratory Parameter:"は、画面に表示される説明文です。ユーザーはここで、ALT、AST、Hemoglobinなどadlbcに含まれる任意の検査項目を選べます。
choices = unique(dat_clean$PARAM) はプルダウンで選べる候補の一覧です。ここでは「重複しない項目名」を自動取得しているため、データが変わっても手動更新する必要がありません。
selected = unique(dat_clean$PARAM)[1]は、最初に表示する項目を先頭 (1つ目) に自動設定します。これにより、Shiny アプリを開いた瞬間に白画面を避けることができます。
checkboxGroupInput() は、比較したい治療群 (TRTP) を選択できるようにするために入れました。複数の治療群を自由に ON/OFF できる仕組みです。
ヒト臨床試験 (ヒト試験) のデータを用いる場合は、汎用性の高い部分だと思います。choices = unique(dat_clean$TRTP) は、治療群を自動抽出します。selected = unique(dat_clean$TRTP) は、デフォルトで全群選択にしているのがポイントで、ユーザーは不要な群を外して比較することができます。
ここまでのコードをまとめると以下の通りです:
# ===============================================
# UI Layout
# ===============================================
ui <- dashboardPage(
dashboardHeader(title = "ADLBC Explorer"),
# ----------------------------------------------------------
# Sidebar: パラメータ選択、群選択
# ----------------------------------------------------------
dashboardSidebar(
selectInput(
inputId = "param",
label = "Select Laboratory Parameter:",
choices = unique(dat_clean$PARAM),
selected = unique(dat_clean$PARAM)[1]
),
checkboxGroupInput(
inputId = "groups",
label = "Select Treatment Groups:",
choices = unique(dat_clean$TRTP),
selected = unique(dat_clean$TRTP)
)
),
# ----------------------------------------------------------
# Main Body: 3つの可視化コンポーネント
# ----------------------------------------------------------
dashboardBody(
fluidRow(
box(width = 12, title = "Mean Profile Plot", status = "primary",
solidHeader = TRUE, plotOutput("meanPlot", height = "350px"))
),
fluidRow(
box(width = 12, title = "Boxplot by Visit", status = "info",
solidHeader = TRUE, plotOutput("boxPlot", height = "350px"))
),
fluidRow(
box(width = 12,
title = "Summary Statistics Table (Matrix Format)",
status = "warning",
solidHeader = TRUE,
uiOutput("summaryTable"))
)
)
)これでUI部分を準備できました。次は、SERVERを準備します。
3.4 SERVERを作成する
Serverはデータ処理・解析ロジック・描画を担当します。
ダッシュボードの操作に応じて解析対象を切り替えるため、まず最初に「reactive データ」を定義します。
dat_filtered <- reactive({
req(input$param)
dat_clean %>%
filter(PARAM == input$param,
TRTP %in% input$groups)
})ユーザーが選択したPARAM (検査項目) とTRTP (治療群) をもとに対象データが自動的に絞り込まれる仕組みです。
Shinyのreactiveモデルにより、ここで生成されたデータは、後続のグラフ・表が呼び出すたびに最新状態へ更新されます。このリアクティブ性が、Shinyを使ったインタラクティブ解析の中核となります。
続いて、可視化のための準備をしていきます。
1つ目は、群別の平均推移 (Mean Profile) です。
output$meanPlot <- renderPlot({
df <- dat_filtered()
ggplot(df, aes(x = AVISITN, y = AVAL, color = TRTP, group = TRTP)) +
stat_summary(fun = mean, geom = "line", size = 1) +
stat_summary(fun = mean, geom = "point", size = 2) +
scale_x_continuous(
breaks = sort(unique(df$AVISITN)),
labels = df %>% distinct(AVISITN, AVISIT) %>% arrange(AVISITN) %>% pull(AVISIT)
) +
labs(
title = paste("Mean Profile:", input$param),
x = "Visit", y = "Mean Value"
) +
theme_bw() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
})個々の測定値ではなく、Visitごとの平均値を描くことで群間のトレンドを直感的に把握できます。また、x軸には数値のAVISITNを使いつつ、ラベル表示にはBaselineやWeek 4といったAVISITを用いることで、現場で馴染みのある形式に整えています。
次は、箱ひげ図 (Boxplot) です。
output$boxPlot <- renderPlot({
df <- dat_filtered()
df <- df %>%
arrange(AVISITN) %>%
mutate(AVISIT = factor(AVISIT, levels = unique(AVISIT)))
ggplot(df, aes(x = AVISIT, y = AVAL, fill = TRTP)) +
geom_boxplot() +
labs(
title = paste("Distribution by Visit:", input$param),
x = "Visit", y = "Value"
) +
theme_bw() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
})箱ひげ図 (Boxplot) は、外れ値や分布の偏り、群間の位置の違いなどを迅速に把握できるため、データレビューでは必須の可視化手法ですよね。ここでも来院順が崩れないよう、factorレベルをAVISITNで明示的に整列しています。
最後に、要約統計表 (Summary Matrix) です。記述統計を群 × Visitのマトリクス形式で表示する表であり、よく論文などでも用いられている表です。
output$summaryTable <- renderUI({
df <- dat_filtered()
# ---- Visit × Group × Statistic を集計 ----
df_sum <- df %>%
group_by(AVISITN, AVISIT, TRTP) %>%
summarise(
n = sum(!is.na(AVAL)),
Mean = formatC(mean(AVAL, na.rm = TRUE), format = "f", digits = 1),
SD = formatC(sd(AVAL, na.rm = TRUE), format = "f", digits = 1),
Median = formatC(median(AVAL, na.rm = TRUE), format = "f", digits = 1),
Min = formatC(min(AVAL, na.rm = TRUE), format = "f", digits = 1),
Max = formatC(max(AVAL, na.rm = TRUE), format = "f", digits = 1),
.groups = "drop"
)
groups <- unique(df_sum$TRTP)
stats <- c("n", "Mean", "SD", "Median", "Min", "Max")
# ---- Wide 形式に変換(群 × 統計量) ----
df_wide <- df_sum %>%
tidyr::pivot_wider(
names_from = TRTP,
values_from = stats,
names_glue = "{TRTP}_{.value}"
) %>%
arrange(AVISITN)
# 列順を group × stats の順に強制整列
ordered_cols <- c("AVISITN", "AVISIT",
unlist(lapply(groups, function(g) paste0(g, "_", stats))))
df_wide <- df_wide[, ordered_cols]
# ---- 二段ヘッダー定義 ----
header_top <- c(" " = 2)
for (g in groups) header_top[g] <- length(stats)
header_bottom <- c("AVISITN", "AVISIT", rep(stats, length(groups)))
# ---- kableExtra による表描画 ----
tbl_html <- df_wide %>%
kableExtra::kbl(
booktabs = TRUE,
col.names = header_bottom,
caption = paste("Summary Statistics:", input$param)
) %>%
kableExtra::add_header_above(header_top) %>%
kableExtra::kable_classic(full_width = FALSE, html_font = "Roboto") %>%
kableExtra::kable_styling(
bootstrap_options = c("striped", "hover", "condensed", "bordered"),
full_width = TRUE
) %>%
kableExtra::row_spec(0, bold = TRUE, background = "#f0f0f0")
# テーブルを左寄せで配置
HTML(tbl_html)
})
}ここでは、群別にn、mean、SD、median、min、maxを算出し、さらにpivot_widerにより横長形式へ整形します。
最終的にはkableExtraによって表をHTML形式で整形し、報告書レベルの読みやすい二段ヘッダー付きテーブルとして出力します。
要約統計のマトリクスは、報告書や論文で特に重要な形式であり、Shinyを使うことで手間を大幅に削減できる可能性がります。
server部分のコードを以下にまとめます:
# ===============================================
# SERVER Logic
# ===============================================
server <- function(input, output, session) {
# ----------------------------------------------------------
# Reactive: 選択された PARAM / TRTP に基づく subset
# ----------------------------------------------------------
dat_filtered <- reactive({
req(input$param)
dat_clean %>%
filter(PARAM == input$param,
TRTP %in% input$groups)
})
# ----------------------------------------------------------
# 1. Mean Profile Plot(群別平均推移)
# ----------------------------------------------------------
output$meanPlot <- renderPlot({
df <- dat_filtered()
ggplot(df, aes(x = AVISITN, y = AVAL, color = TRTP, group = TRTP)) +
stat_summary(fun = mean, geom = "line", size = 1) +
stat_summary(fun = mean, geom = "point", size = 2) +
scale_x_continuous(
breaks = sort(unique(df$AVISITN)),
labels = df %>% distinct(AVISITN, AVISIT) %>% arrange(AVISITN) %>% pull(AVISIT)
) +
labs(
title = paste("Mean Profile:", input$param),
x = "Visit", y = "Mean Value"
) +
theme_bw() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
})
# ----------------------------------------------------------
# 2. Boxplot(群 × Visit の分布)
# ----------------------------------------------------------
output$boxPlot <- renderPlot({
df <- dat_filtered()
df <- df %>%
arrange(AVISITN) %>%
mutate(AVISIT = factor(AVISIT, levels = unique(AVISIT)))
ggplot(df, aes(x = AVISIT, y = AVAL, fill = TRTP)) +
geom_boxplot() +
labs(
title = paste("Distribution by Visit:", input$param),
x = "Visit", y = "Value"
) +
theme_bw() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
})
# ----------------------------------------------------------
# 3. Summary Statistics Table(マトリクス形式集計)
# ----------------------------------------------------------
output$summaryTable <- renderUI({
df <- dat_filtered()
# ---- Visit × Group × Statistic を集計 ----
df_sum <- df %>%
group_by(AVISITN, AVISIT, TRTP) %>%
summarise(
n = sum(!is.na(AVAL)),
Mean = formatC(mean(AVAL, na.rm = TRUE), format = "f", digits = 1),
SD = formatC(sd(AVAL, na.rm = TRUE), format = "f", digits = 1),
Median = formatC(median(AVAL, na.rm = TRUE), format = "f", digits = 1),
Min = formatC(min(AVAL, na.rm = TRUE), format = "f", digits = 1),
Max = formatC(max(AVAL, na.rm = TRUE), format = "f", digits = 1),
.groups = "drop"
)
groups <- unique(df_sum$TRTP)
stats <- c("n", "Mean", "SD", "Median", "Min", "Max")
# ---- Wide 形式に変換(群 × 統計量) ----
df_wide <- df_sum %>%
tidyr::pivot_wider(
names_from = TRTP,
values_from = stats,
names_glue = "{TRTP}_{.value}"
) %>%
arrange(AVISITN)
# 列順を group × stats の順に強制整列
ordered_cols <- c("AVISITN", "AVISIT",
unlist(lapply(groups, function(g) paste0(g, "_", stats))))
df_wide <- df_wide[, ordered_cols]
# ---- 二段ヘッダー定義 ----
header_top <- c(" " = 2)
for (g in groups) header_top[g] <- length(stats)
header_bottom <- c("AVISITN", "AVISIT", rep(stats, length(groups)))
# ---- kableExtra による表描画 ----
tbl_html <- df_wide %>%
kableExtra::kbl(
booktabs = TRUE,
col.names = header_bottom,
caption = paste("Summary Statistics:", input$param)
) %>%
kableExtra::add_header_above(header_top) %>%
kableExtra::kable_classic(full_width = FALSE, html_font = "Roboto") %>%
kableExtra::kable_styling(
bootstrap_options = c("striped", "hover", "condensed", "bordered"),
full_width = TRUE
) %>%
kableExtra::row_spec(0, bold = TRUE, background = "#f0f0f0")
# テーブルを左寄せで配置
HTML(tbl_html)
})
}3.5 仕上げ
Shinyの基本構造は必ず、
UI (見た目の部分)
Server (裏側の処理)
の2つで成り立っています。
ui <- dashboardPage(...)
server <- function(input, output, session) { ... }これらを実際にアプリとして稼働させるために、最後に必ず以下のコードを入れます。
# ===============================================
# Run App
# ===============================================
shinyApp(ui, server)これを記述した時点で、R は「ここからWebアプリを始めなさい」と理解します。
これで、アプリを公開することができます。
ダッシュボードを見てみる
今回のコードで作成したダッシュボードを見ていきましょう。
作成したダッシュボードは、shinyapps.ioにアップロードしました。
shinyapps.ioは、Rで作成したShinyアプリをインターネット上に簡単に公開できる、Posit (旧RStudio) が提供するクラウドサービスです。サーバー構築や環境設定が不要で、RStudioから数クリックでデプロイできます。
このURLから閲覧できます。
https://statisticalanalysistoukeikaiseki.shinyapps.io/ADLBC_app/
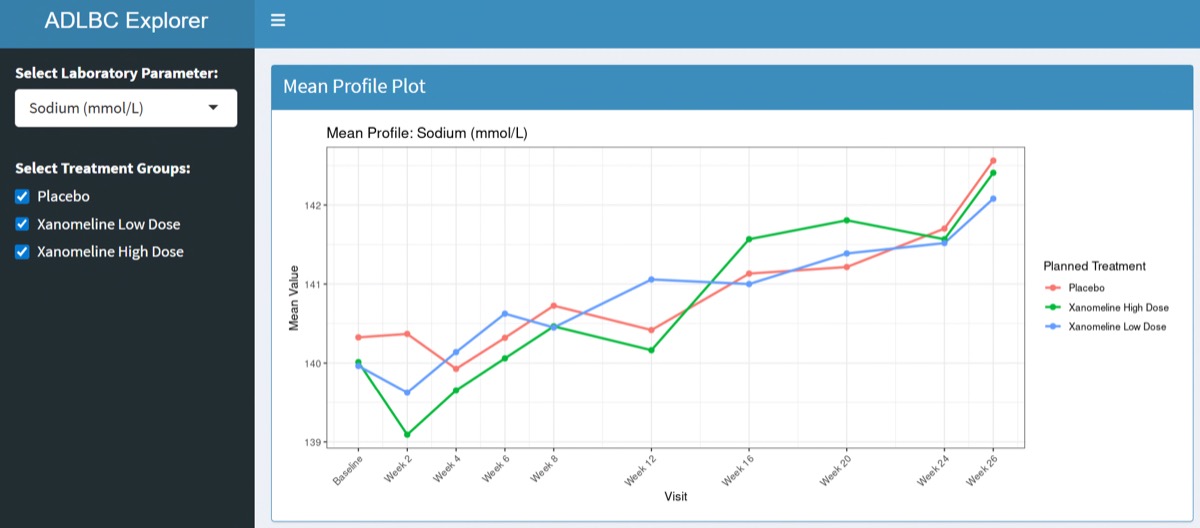
下にスクロールすると・・・
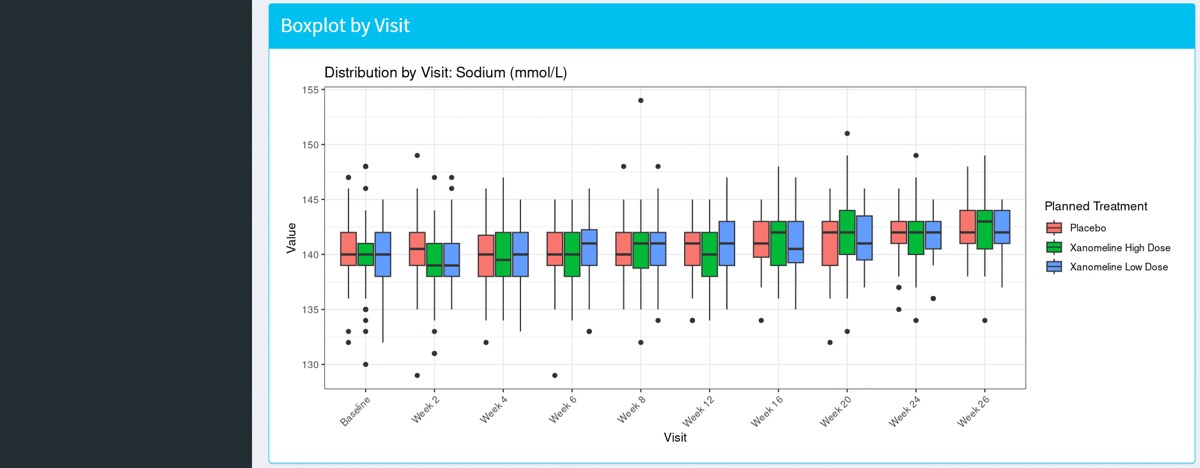
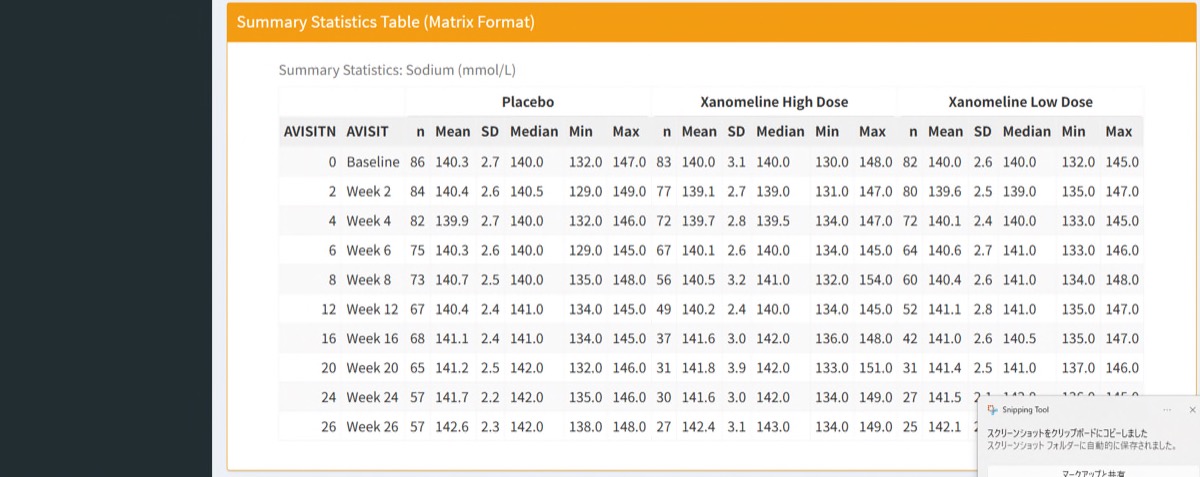
目標とした3つの図表が生成されていますね。
左上のチェックボックスで、表示する群を変えることができます。
さらに、Select Laboratory Parameterで表示する検査項目を変えることができます。
うまく機能していますね。
まとめ
本稿では、tidyCDISCに含まれるADaM形式の臨床検査データ (ADLBC) を対象に、Shinyを用いて「平均推移」「分布」「要約統計」をワンクリックで確認できるダッシュボードを作成しました。
臨床検査データは、項目数、来院回数、治療 (介入) 群が多くなるにつれ、スクリプトベースでの可視化やデータ品質チェックには時間がかかるものです。
しかし Shiny を活用すると、
- 自動フィルタリングによる柔軟なデータ切り替え
- リアクティブに更新されるグラフと表
- UIと操作性を両立したダッシュボード型アプリ
が簡潔なRコードだけで実現できることが分かりました。
とくに、ADaM-BDS形式のデータとShinyの相性は非常に良く、探索的解析 (EDA)、品質チェック、依頼者とのコミュニケーションにも応用できると思います。
- 複数検査項目を瞬時に比較
- 群間のばらつきを可視化
- Visit × 群の記述統計を自動生成
といった作業は、日々の統計解析の効率化に直結します。
今回紹介したコードは、あくまで基本形です。用途に応じて自由に拡張してみてください。
統計解析.comでは、今回のような Shiny を活用した可視化だけでなく、今後は より幅広い統計解析手法・可視化技術・データ処理ワークフロー をR・Python 両方の視点から紹介していく予定です。
臨床試験・機能性表示食品・ヘルスケアデータ解析など、現場で直面しやすい課題を中心に、
- Rのtidyverseやggplot2を使った再現性の高い可視化
- Shiny / shinydashboardによるインタラクティブな業務改善
- Python (pandas・plotly・Dash) の可視化や自動化スクリプト
- 実務で役立つ統計モデリング (ANCOVA・MMRM・ロジスティック回帰など)
- データ品質管理 (EDITCHECK・SDTM/ADaM の整形・探索的解析)
- RWD・ビジネスデータへの応用例
など、幅広く扱っていきます。
特に、可視化・レポート生成・ダッシュボード構築は、統計解析担当者だけでなく、研究者・企画担当者・品質管理部門にとっても業務効率化と意思決定のスピードを大きく高める重要なテーマです。
「現場で本当に使える統計解析」「すぐに業務に持ち帰れるコードと知見」をコンセプトに、今後も内容を充実させていきます。
ぜひ引き続きご覧いただき、業務や研究の一助として活用していただければ幸いです。
